
日前,在2019 英特尔人工智能峰会期间(Intel AI Summit 2019),英特尔向外界展示了一系列 AI 相关新产品。包括英特尔 Nervana 细列神经网络处理器 (NNP) 和新一代 Movidius Myriad 视觉处理单元。英特尔的老对手NIVIDA一直是AI芯片领域的霸主,仰仗平台优势和先发优势,NVIDIA已经占据AI市场的半壁江山。英特尔这头大象反应虽慢,此次正面出击,也给人工智能市场带来更多的选择。
随着人工智能的进一步发展,传统处理器在这一领域的性能表现十分有限。人工智能专用型硬件是必不可少的,不同商家的可能不一样如NPU,APU等,到英特尔这里就成了 Nervana NNP 和 Movidius Myriad VPU。目前Nervana NNP 已经投入生产并交付。
Nervana NNP 是Intel在神经网络处理器方面的重要产品,可以说是第一款 AI 商用芯片,而且这款产品从发布、测试、量产到应用,实际上是经历了一个漫长的产品周期。相比NVIDIA早早布局AI市场和软件生态,Intel在人工智能领域发力确实晚了些,不过这不影响开发者的选择,毕竟Intel多年来有着稳固且庞大的销售网络,有着忠实的追随者。
 新一代 Nervana NNP 名称有些变化,Nervana NNP-T 代号 Spring Crest,采用了台积电的 16nm FF+ 制程工艺,拥有 270 亿个晶体管,硅片面积 680 平方毫米,能够支持 TensorFlow、PaddlePaddle、PYTORCH 训练框架,也支持 C++ 深度学习软件库和编译器 nGraph。而 Nervana NNP-I,代号为 Spring Hill,是一款专门用于大型数据中心的推理芯片。这款芯片是基于 10nm 技术和 Ice Lake 内核打造的,打造地点是以色列的 Haifa ,Intel 号称它能够利用最小的能量来处理高负载的工作,它在 ResNet50 的效率可达 4.8TOPs/W,功率范围在 10W 到 50W 之间。
新一代 Nervana NNP 名称有些变化,Nervana NNP-T 代号 Spring Crest,采用了台积电的 16nm FF+ 制程工艺,拥有 270 亿个晶体管,硅片面积 680 平方毫米,能够支持 TensorFlow、PaddlePaddle、PYTORCH 训练框架,也支持 C++ 深度学习软件库和编译器 nGraph。而 Nervana NNP-I,代号为 Spring Hill,是一款专门用于大型数据中心的推理芯片。这款芯片是基于 10nm 技术和 Ice Lake 内核打造的,打造地点是以色列的 Haifa ,Intel 号称它能够利用最小的能量来处理高负载的工作,它在 ResNet50 的效率可达 4.8TOPs/W,功率范围在 10W 到 50W 之间。
按照官方说法,英特尔 Nervana 神经网络训练处理器(Intel Nervana NNP-T)在计算、通信和内存之间取得了平衡,不管是对于小规模群集,还是最大规模的 pod 超级计算机,都可进行近乎线性且极具能效的扩展。英特尔 Nervana 神经网络推理处理器(Intel Nervana NNP-I)具备高能效和低成本,且其外形规格灵活,非常适合在实际规模下运行高强度的多模式推理。这两款产品面向百度、 Facebook 等前沿人工智能客户,并针对他们的人工智能处理需求进行了定制开发。

此外,Intel 公布了全新一代 Movidius VPU。下一代英特尔 Movidius VPU 的代号是 Keem Bay,它是专门为边缘 AI 打造的一款产品,专注于深度学习推理、机器视觉和媒体处理等方面,采用全新的高效能架构,并且通过英特尔的 OpenVINO 来加速。按照官方数据,它在速度上是英伟达 TX2 的 4 倍,是华为海思 Ascend 310 的 1.25 倍。另外在功率和尺寸上,它也远远超过对手。
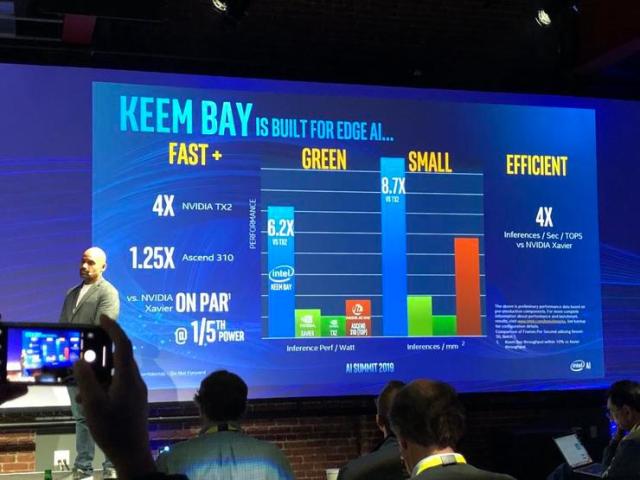 Intel 方面表示,新一代 Movidius 计划于 2020 年上半年上市,它凭借独一无二的高效架构优势,能够提供业界领先的性能:与上一代 VPU 相比,推理性能提升 10 倍以上,能效则可达到竞品的 6 倍。除了新一代 Movidius,英特尔还发布了全新的英特尔 DevCloud for the Edge,该产品旨在与英特尔 Distribution of OpenVINO 工具包共同解决开发人员的主要痛点,即在购买硬件前,能够在各类英特尔处理器上尝试、部署原型和测试 AI 解决方案。
Intel 方面表示,新一代 Movidius 计划于 2020 年上半年上市,它凭借独一无二的高效架构优势,能够提供业界领先的性能:与上一代 VPU 相比,推理性能提升 10 倍以上,能效则可达到竞品的 6 倍。除了新一代 Movidius,英特尔还发布了全新的英特尔 DevCloud for the Edge,该产品旨在与英特尔 Distribution of OpenVINO 工具包共同解决开发人员的主要痛点,即在购买硬件前,能够在各类英特尔处理器上尝试、部署原型和测试 AI 解决方案。
另外,英特尔还介绍了自家的英特尔至强可扩展处理器在 AI 方面的进展。可见,在推进 AI 技术走向商用落地方面,英特尔终于跨出了自信的一步。











