伴随着人工智能技术的飞速发展,大语言模型(Large Language Model,简称LLM)的应用也日益增长,其性能也十分出色,可以说AI的语言能力已经十分优秀。各种行业对LLM的需求与日俱增,本文将进行简单的技术分析,告诉大家如何快速的落地一个基于大语言模型的智能语音交互设备。
大语言模型(LLM)可以赋能的智能语音交互设备
 理论上讲,凡是有智能语音功能的产品都可以用LLM重新做一遍。在智能交互过程中,语音识别、语意处理和语音合成是三个核心技术,LLM实际取代的是语义处理部分,而语意处理恰好是评价一个模型是否足够智能的主要维度。如今LLM发展迅猛,原有的语意处理模型早已淘汰,因此,很多产品都可以用LLM重新设计开发。下面是一些常见的智能语音交互设备,可供大家参考。
理论上讲,凡是有智能语音功能的产品都可以用LLM重新做一遍。在智能交互过程中,语音识别、语意处理和语音合成是三个核心技术,LLM实际取代的是语义处理部分,而语意处理恰好是评价一个模型是否足够智能的主要维度。如今LLM发展迅猛,原有的语意处理模型早已淘汰,因此,很多产品都可以用LLM重新设计开发。下面是一些常见的智能语音交互设备,可供大家参考。
- 智能家居设备:如智能音箱、智能中控屏、智能照明、智能安防系统等,LLM可以通过自然语言处理技术提升这些设备的交互能力和智能化水平。
- 智能穿戴设备:如智能手表和健康追踪器,LLM可以帮助这些设备更好地理解用户指令,提供个性化的健康建议和提醒服务。
- 智能办公设备:如智能会议系统、办公助理等,LLM能够提升工作效率,通过语音或文本交互完成会议记录、日程安排、翻译等任务。
- 教育和辅助学习设备:LLM可以应用于教育机器人、在线教育平台,提供个性化学习内容和辅导。
- 个人助理设备:LLM可以作为个人助理,通过语音或文本交互帮助用户管理日常任务和提醒。
- 客户服务机器人:在商业领域,LLM可以用于自动化客服系统,提供更加智能化的客户服务和支持。
LLM的集成能够使这些智能设备更加人性化、个性化,并提高其自主决策和学习的能力。如今LLM正处于高速发展期,相信随着产品迭代,其用户体验也将指数级上升。
 语音识别的实现
语音识别的实现
语音交互的开始,说给机器听,让机器听明白人的话。就现阶段的主流技术而言,我们是同过文本跟机器沟通的,要让AI知道我们在说什么,那么就有个STT(语音转文本)的过程,语音识别技术应运而生。语音识别(ASR):使用麦克风或其他音频输入设备捕捉用户的语音。将捕捉到的语音数据转换成数字信号,提取语音特征,使用深度学习模型,如循环神经网络(RNN)或Transformer模型,将语音特征映射为文本。
在这个过程中有两点需要注意,第一是要确保采集到高质量的用户语音,第二则是语音映射文本的算法模型。采集用户语音主要涉及声学结构设计和前端算法(如增益、降噪等算法),大多数高精度的算法都会有对应的结构要求,在做产品设计时需要选好技术方案。语音映射文本有多种实现方式,可以使用服务商的在线模型(如百度、讯飞的相关模型),本地调用API,将音频退到服务器即可。还可以使用服务商提供的离线模型,或者自己部署端侧的语音识别模型。
LLM井喷式出现
LLM进行语意处理
大语言模型已经足够聪明,完全可以胜任人机对话,尤其是采用多模态的LLM,表现更加优异。通过对话管理,设计对话流程,包括用户意图识别、对话状态跟踪和上下文管理。根据用户的输入和历史对话,维护对话状态,确保回复的相关性和连贯性。实现上下文理解的边界设定,避免混淆不同任务指令。对于一个快速落地的项目,我们只要选择合适的大语言模型进行语意处理即可。可以直接通过网络调用服务商(如Kimi、Chat GPT、文心一言等模型)的相关API,将文本内容输入,得到LLM的输出内容。也可以在端侧部署开源模型,甚至是在终端设备直接部署参数较少的LLM。若是选择端侧离线模型,模型的甄选、算力的评估、产品的成本都是重点考虑的因素。
语音合成让我们听到AI的反馈
拿到输出文本后就要进行语音合成了,也就是文本到语音(TTS),将LLM生成的文本通过TTS技术转换成语音输出。选择合适的语音合成模型,如参数合成器或基于神经网络的合成器。调整语音的参数,如音调、语速和情感,以生成听起来更加自然的语音。当然,除了语音交互,画面显示、控制动作也可以作为输出内容,这个就是产品形态问题了。
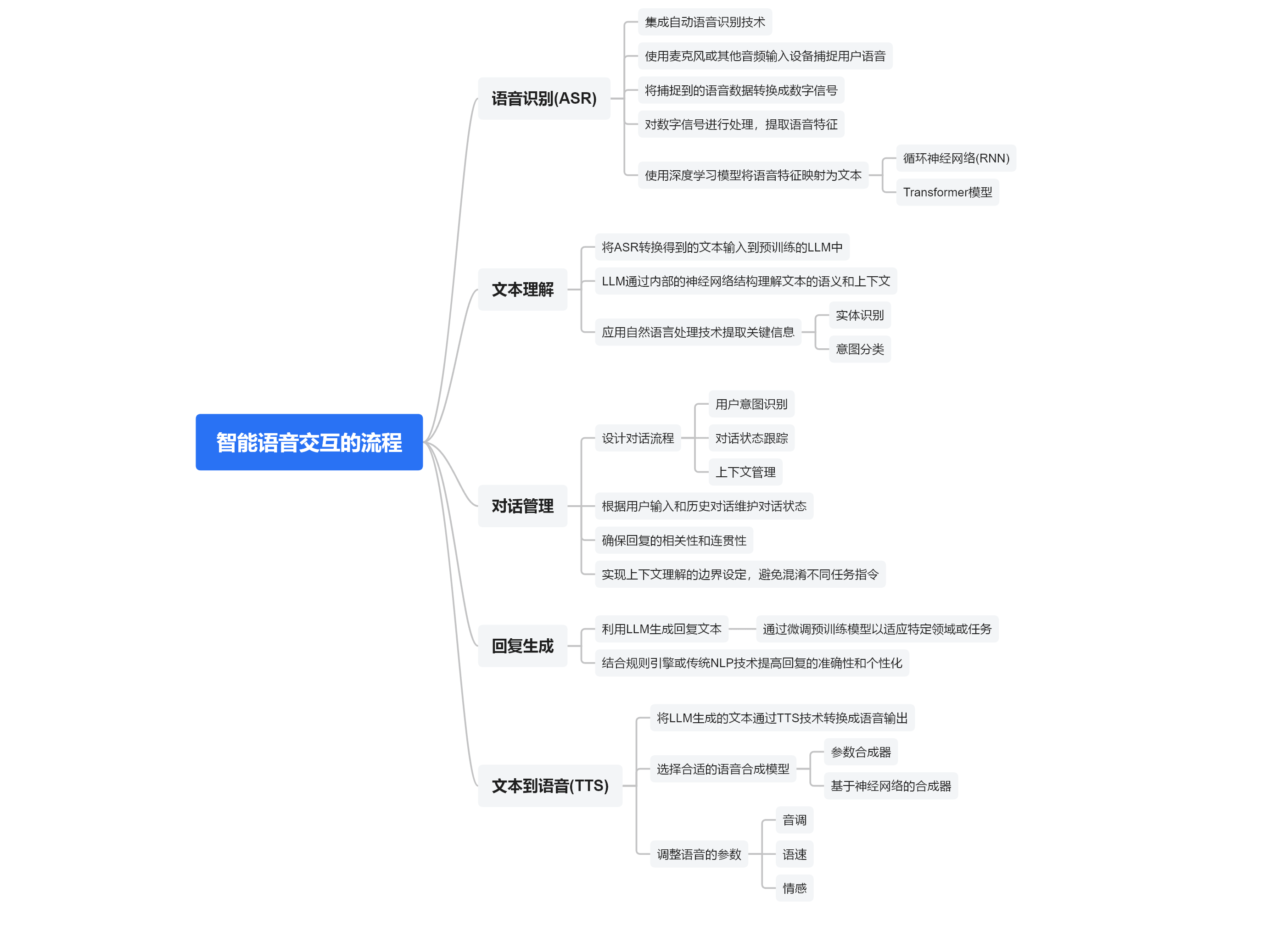
智能语音交互的流程
技术不复杂,产品定义才是关键
由上面分析可见,智能语音交互技术的核心原理和实现方式并不复杂,但如何将这些技术有效转化为用户真正需要和喜爱的产品才是更大的挑战。LLM的能力是多样化的,并且依然处于高速发展期,科技为我们提供了强大的生产力。当我们使用这些先进科技时要具备创造性思维,打破传统的枷锁,尝试不同的产品场景,给用户带来优秀的产品体验。同样的,任何产品都要合法合规,同时需要尽可能地避开潜在风险。就LLM的应用来看,数据隐私绝对是绕不过去的问题。原因也很简单,LLM是基于大数据训练得来的,没有海量真实有效的数据样本,其发展也会受限。
产品迭代维护也是非常重要的一环。收集用户反馈和系统性能数据,用于评估交互体验。根据评估结果,调整LLM的参数,优化对话管理和回复生成策略。持续更新训练数据,以包含新的对话场景和用户意图。技术框架的选择对后期的运营维护十分重要,灵活的技术框架可以实现低成本的快速迭代。
选择合适的智能语音交互SoC芯片
我们以国产的瑞芯微SoC芯片为例,如RK3308、RK3562、RK3576和RK3588,分析下它们适应的产品方案。
- RK3308:
- 专为智能语音交互、音频输入/输出处理和其他数字多媒体应用而设计的应用处理器。
- 四核ARM Cortex-A35 CPU,优化了音频接口和CODEC,支持最大8通道模拟MIC阵列。
- 针对音频和IoT应用进行了成本和系统优化,提供了高性价比的解决方案。
- 丰富的音频接口,如I2S、PCM等,以及多种数字音频输入输出接口。
- 适用于智能音箱、智能语音等场景,也可用于其他需要音频处理的场合。
- 非常适合全网络调用的技术方案,即语音识别、语意处理、语音合成均采用在线的API调用。
- 硬件成本低,后期规模化运营需承担API的费用。
- RK3562:
- 采用四核A53架构,主频2GHz,内置1T NPU算力以及13M ISP。
- 支持H.264 1080P@60fps、H.265 4K@30fps解码,以及H.264 1080P@60fps编码。
- 包含3D GPU,支持OpenGL ES1.1/2.0/3.2, OpenCL 2.0,Vulkan 1.1。
- 拥有丰富的外围接口,适用于高性能计算和图形处理需求的应用。
- 可以应用于学习平板、词典笔、智慧屏、语音助手等产品。
- 除了联网调用端口,还可以考虑将语音识别和语音合成的模型部署在本地,
- RK3576:
- 低功耗、高性能的通用型SoC处理器,适用于ARM架构的PC、边缘计算设备等。
- 八核心CPU,主频高达2.2GHz,支持高端视频编解码能力。
- 具备新一代ISP和强大的NPU,NPU可提供6TOPS算力支持。
- 支持多种计算核心和丰富的外设接口,最大支持16GB LPDDR5内存。
- 适用于智慧大屏、交互机器人、视频会议终端、智慧教室终端等产品。
- 可以考虑在设备上直接部署小参数的LLM,做到数据本地化管理,保障数据安全。
- RK3588:
- 一款低功耗、高性能处理器,适用于ARM PC、边缘AI设备、汽车电子、边缘计算服务器等。
- 集成四核Cortex-A76和四核Cortex-A55,主频高达2.4GHz,最大运行内存32GB,支持8K视频解码和编码。
- 内置48M ISP、NPU、GPU、VPU、MCU等核心,支持多种混合运算,具备高性能的图像处理和AI计算能力。
- 具备多种高速接口,可实现高性能的快速拓展。
- 支持芯片协同技术,支持三颗SoC芯片协同,提供三倍性能。
- 可以作为语音交互的本地服务器使用,选择部署依赖DDR的大语言模型,向内网设备提供网络服务。
结语:
不同的芯片,所能承载的语音交互方案大相径庭。如何定义产品,选择合适的技术路线,是对产品经理的大考验。本文仅从技术角度向大家分享如何快速落地一个基于大语言模型智能语音交互设备,希望对大家有所帮助。
版权声明:原创文章,转载须注明出处:ScenSmart智造平台。